Link building is niet zo gemakkelijk. Het vraagt veel tijd en kan een heel frustrerend proces zijn. Spijtig genoeg is het meestal niet alleen een kwestie van goede content die automatisch een hele resem links krijgt. De meeste content, zelfs heel goede content, heeft een duwtje in de rug nodig om hem links te doen krijgen. Hoe meer ervaring je hierin hebt/krijgt, hoe vlotter het gaat – maar het is en blijft wel een stevig werkje. Af en toe zijn er echter een aantal easy-to-get links te scoren, en die wil je natuurlijk niet missen. Hieronder drie simpele links die jij vandaag al kan scoren – zomaar gratis en voor niks!
13
mrt
08
mrt
Het gebruik van “rich snippets” in zoekresultaten
De zoekresultaten zoals we die tegenwoordig in Google aantreffen, hebben er zeker niet altijd hetzelfde uitgezien. In de loop der jaren hebben ze bij de zoekmachine namelijk allerhande lay-out aanpassingen uitgeprobeerd om zo de gebruiker de best mogelijke zoekervaring aan te bieden. Zo zie je misschien soms een gemiddelde recensiescore onder een bepaald product, een lijst met beschikbare nummers op een muziek-cd of een afbeelding van de auteur van een blogpost.
Enkele voorbeelden van rich snippets in zoekresultaten


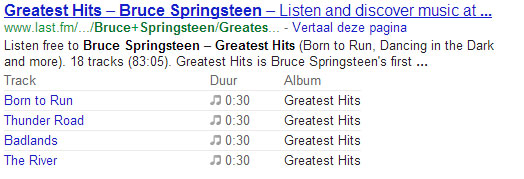
Dergelijke stukjes extra informatie worden ook wel eens rich snippets genoemd. Hun doel is om de gebruiker sneller een beeld te geven van de soort informatie en om te evalueren of die voor hen persoonlijk wel relevant is. Studies hebben bovendien ook al aangetoond dat “searchers” meer geneigd zijn door te klikken op zoekresultaten met rich snippets dan op de droge klassieke variant die enkel een titel en een summiere beschrijving bevat.
26
feb
Hoeveel PageRank is verloren met een 301 redirect?
Veel SEOs zijn overtuigd dat een 301 redirect ofwel alle, ofwel bijna geen PageRank doorspeelt. In deze recente video legt Matt Cutts uit dat 301 redirects bijna exact hetzelfde doen als een gewone link (bijna, want natuurlijk is er bij een 301 geen sprake van een verdeling van de juice).
In de praktijk wil dat zeggen dat er geen reden is om 301 redirects (die we al eerder hadden vermeld in onze vorige blog post) te vermijden wanneer deze interessant zijn voor de gebruiker of voor de usability van uw website.
18
feb
Het belang van .htaccess bestanden
Wat is het?
Het aanmaken van een .htaccess bestand op je Apache webserver is op zich niet zo’n echt ingewikkelde onderneming. Eenvoudig gesteld is het een simpel tekstbestand dat je op de server host en waarmee je door bepaalde commando’s verschillende server-instellingen kunt aanpassen. Zo kan je dergelijke .htaccess bestanden onder meer gebruiken om:
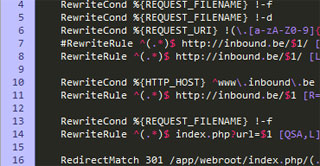
- oude pagina’s te laten doorverwijzen naar hun nieuwe equivalent
- specifieke mappen te beveiligen
- gespecifieerde IP-adressen te blokkeren
- url’s te vertalen in een mooiere, meer overzichtelijke vorm
- …
01
feb
Website copywriting: Waarom is het een unieke vaardigheid?
Iedereen kan schrijven. Misschien is dat iets te breed genomen. Maar waarschijnlijk kunnen de meeste mensen met de intentie om een website op te zetten om iets te verkopen, of het nu producten of ideeën zijn, toch echt wel enkele woorden aan elkaar  rijgen om tot een volwaardige, Nederlandse zin te komen.
rijgen om tot een volwaardige, Nederlandse zin te komen.
Maar schrijven voor het web is, net als reclameteksten schrijven, een vaardigheid op zich. Het is namelijk niet omdat iets correct Nederlands is, dat het iemand zal kunnen overtuigen om – zeker online – verder te lezen. Net zoals “ik verkoop computers” weinig waarschijnlijk iemand zal kunnen overtuigen om onmiddellijk een bestelling te plaatsen.
Twee zaken zijn belangrijk om rekening mee te houden bij web copywriting.
29
jan
Duplicate Content: Wat is het, en hoe kan je het vermijden?
Met “duplicate content” bedoelen we het terugkomen van (grote stukken) tekstuele en andere inhoud over één of meerdere domeinnamen. Dit is een probleem omdat het voor zoekmachines moeilijk is om te kiezen welke url de meest relevante is voor een bepaalde zoekactie. Om de beste zoekervaring te geven zal een zoekmachine bijna nooit verschillende keren dezelfde content tonen voor één zoekopdracht, en gokt ze dus vaak welk de meest originele versie is. Het kan gaan over exacte overeenkomsten of over heel grote gelijkenissen. Soms komt dit door plagiaat, maar meestal is er sprake van duplicate content die per ongeluk in de website is geslopen. Bekende voorbeelden zijn:
zoekmachine bijna nooit verschillende keren dezelfde content tonen voor één zoekopdracht, en gokt ze dus vaak welk de meest originele versie is. Het kan gaan over exacte overeenkomsten of over heel grote gelijkenissen. Soms komt dit door plagiaat, maar meestal is er sprake van duplicate content die per ongeluk in de website is geslopen. Bekende voorbeelden zijn:
- Een pagina die twee of meer verschillende urls heeft, bijvoorbeeld https://inbound.be/ en https://inbound.be/index.php, of http://www.jouwsite.be/ en https://www.jouwsite.be/, of http://www.uwwebsite.be/ en http://uwwebsite.be/
- De printbare versie van een pagina met exact dezelfde inhoud als de versie die aan de surfer wordt getoond
- Websites die zowel een normale versie als een versie voor mobiele surfers heeft met dezelfde inhoud (of terugkerende delen inhoud).
Voor de zoekmachines zorgt dit voor 2 zeer grote duplicate content problemen:
- De zoekmachine weet niet welke pagina op te nemen in zijn index, of welke te tonen voor een bepaalde zoekopdracht. In ’t kort: duplicate content brengt de zoekmachine in verwarring.
- De zoekmachine weet niet waar de autoriteit van een bepaalde pagina te plaatsen (denk aan links, auteurschap, …). Samengevat: de zoekmachine geeft niet één pagina alle autoriteir, maar verspreid deze over een aantal, niet geoptimaliseerde pagina’s.
28
jan
Responsive Web Design: Wat is het en waarom is het belangrijk?
Ons surfgedrag is de voorbije jaren enorm hard gewijzigd. Alsmaar meer mensen beschikken inmiddels over een moderne smartphone en/of tablet, en deze dienen voor heel wat meer dan te bellen of berichtjes te sturen. Alsmaar vaker bezoeken we websites via deze “mobile devices” en niet meer uitsluitend via de grote beeldschermen die met onze computers verbonden zijn. Echter, doordat de beeldresoluties van deze toestellen heel wat lager zijn dan die  van het klassieke beeldscherm zullen websites op een minder duidelijke manier vertoond worden.
van het klassieke beeldscherm zullen websites op een minder duidelijke manier vertoond worden.
Zo gaat bijvoorbeeld de tekst op een webpagina in die mate verkleind worden dat deze haast onleesbaar wordt. Deze mobiele toestellen laten dan wel toe een pagina in te zoomen, maar van een fijne gebruikerservaring is helemaal geen sprake meer. Als web publishers zullen we hier dus iets op moeten vinden.
23
jan
SEO voor gepagineerde inhoud
Bij het verdelen van webinhoud over meerdere pagina’s is het aangewezen waakzaam te zijn. Zonder de nodige voorzorgsmaatregelen kan dit immers ernstige schadelijke gevolgen hebben voor de zoekmachineresultaten van jouw website. Een mogelijk probleem is het optreden van zogenaamde “duplicate content”, iets wat men kost wat kost dient te vermijden. Dit houdt namelijk in dat identieke inhoud bereikbaar is op meerdere verschillende URL’s. Websites met “duplicate content” worden onder meer door Google lager gewaardeerd in de rankings. Een gevolg is ook dat de mogelijke linkwaarde van de webpagina verdeeld wordt over alle verschillende URL’s waardoor diens waarde redelijk beperkt blijven. Vanuit een zoekmachineoptimalisatie standpunt is dat natuurlijk een probleem.
Om web publishers te helpen deze problemen te voorkomen of aan te pakken, heeft Google enige tijd geleden de HTML link elementen rel=”prev” en rel=”next” geintroduceerd. Door gebruik te maken van deze elementen kan je voortaan aanduiden dat er een relatie bestaat tussen meerdere webpagina’s. Gepagineerde inhoud kan heel wat verscheidene vormen hebben zoals een artikel verdeeld over meerdere pagina’s of een webshop die producten aanbiedt op vele pagina’s.
22
jan
Het belang van een snelle website…
Websites worden steeds meer een uitgebreide tool die binnen uw organisatie en naar buiten toe een centrale plaats inneemt. Veel websites zijn stevige brokken code en afbeeldingen, die soms maken dat de eindgebruiker geen optimale ervaring meer heeft bij het bezoeken van uw website. Niet alleen komt dit niet zo professioneel over, het kan, zeker voor e-commerce websites of websites in de technische wereld, zorgen voor klanten die afhaken en zelfs een negatief beeld aan uw organisatie overhouden.
Ook de zoekmachines vinden het belangrijk dat een website snel en vlot geladen wordt. Google heeft al, bij monde van Matt Cutts, openlijk toegegeven dat ze de snelheid van een website als een factor gebruiken bij het bepalen van de volgorde van de natuurlijke zoekresultaten.